热线电话:0755-23712116
邮箱:contact@shuangyi-tech.com
地址:深圳市宝安区沙井街道后亭茅洲山工业园工业大厦全至科技创新园科创大厦2层2A


卷积核作为卷积神经网络的基本组成,其直接影响了网络的性能。选择合适的卷积核可以让模型更高效,或者是提高模型的精度。本文介绍了近年来主要的卷积核类型,这里首先我们需要解释一下CNN中广泛使用的卷积运算是一个误称。严格地说,所使用的运算是相关(Correlation)运算,而不是卷积(Convolution)运算。先分别理解这两个运算符的细微差别。
1.Convolution VsCorrelation
1.1相关 (Correlation)
相关是在图像上移动一个通常被称为核的滤波器,并计算每个位置的乘积之和的过程。换句话说,相关运算的第一个值对应于滤波器的零位移,第二个值对应于位移的一个单位,依此类推。
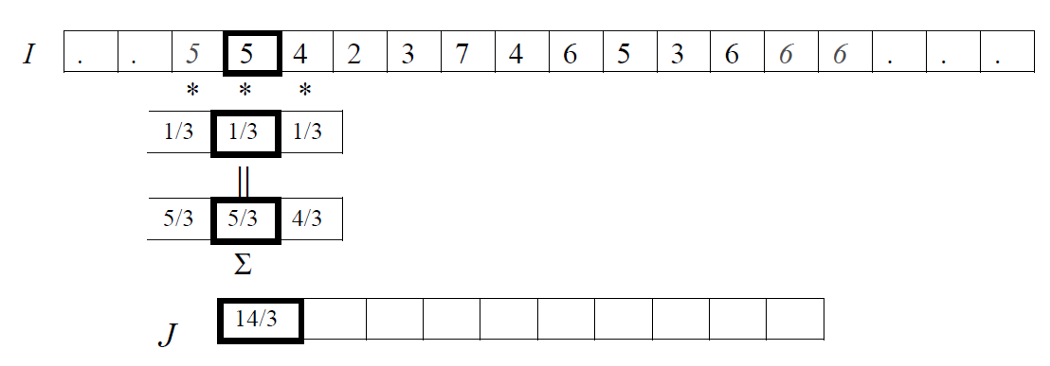
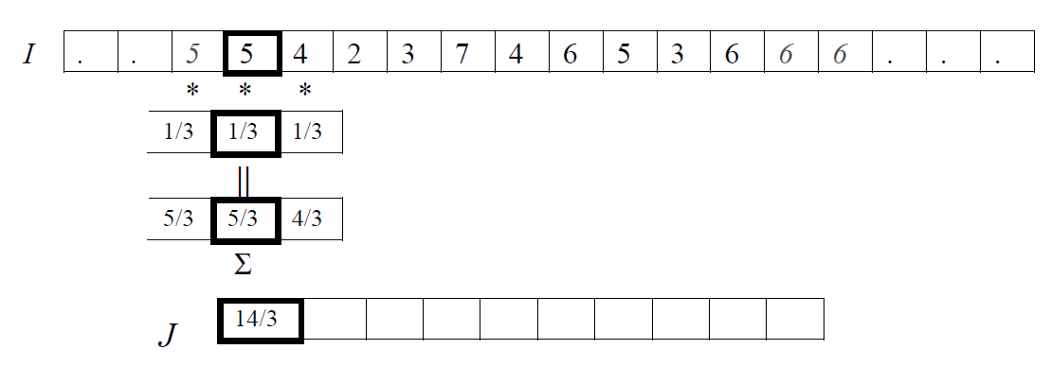
如下公式给出了使用滤波器 F 对输入数据 I 进行一维相关运算的数学公式。我们假设 F 有奇数个元素,所以当它移动时,它的中心就在图像 I 的一个元素上。所以我们说 F 有2N+1个元素,这些元素从-N索引到N,所以F的中心元素是F(0)。
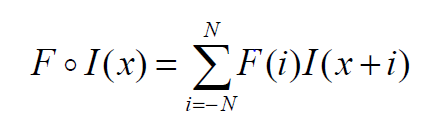
类似地,我们可以将这个概念扩展到二维,如下。基本思想是一样的,除了图像和滤波器现在是二维的,可以假设滤波器有奇数个元素,所以它用(2N+1)x(2N+1)矩阵表示。
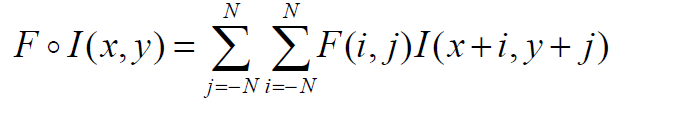
二维中的相关运算非常直接。我们只需取一个给定大小的滤波器,并将其放置在图像中与滤波器大小相同的局部区域上,然后滑动继续进行同样的操作。这样的操作具有两个特性:
· 平移不变性:视觉系统能够感知到同一个物体,而不管它出现在图像中的什么位置。
· 局部感知性:视觉系统专注于局部区域,而不考虑图像的其他部分发生了什么。
1.2卷积(Convolution)
卷积运算与互相关运算非常相似,但略有不同。在卷积运算中,核先翻转180度,然后应用于图像。数学公式如下:
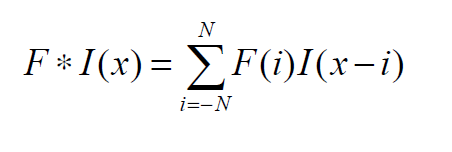
在二维卷积的情况下,我们水平和垂直翻转滤波器。这可以写成:

卷积运算同样具有平移不变性和局部感知性的性质。
需要申明的是:
· 神经网络中的卷积其实是数学上的相关运算;
· 本文接下来出现的卷积,从数学上看都是相关运算。
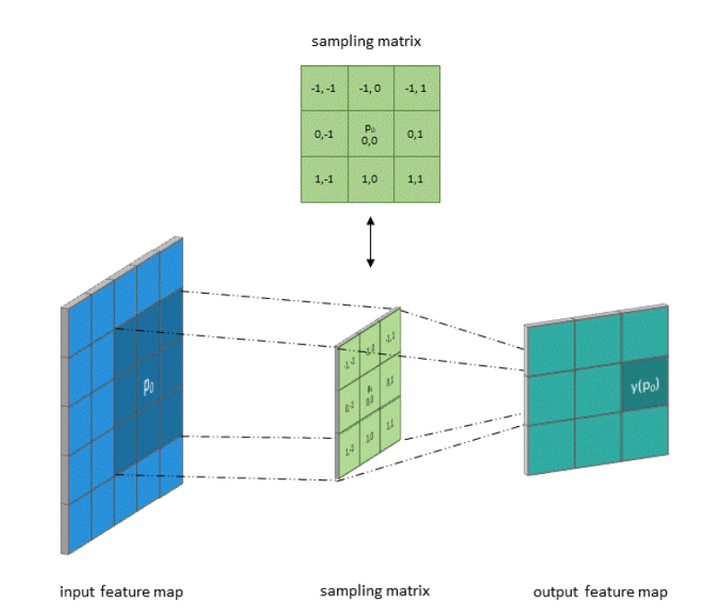
1.3卷积和采样矩阵
标准卷积可以看作在图像上应用采样矩阵(Sampling Matrix)来加权输入的样本,如下图所示,使用的卷积核大小为3、步长为1且没有填充的采样矩阵。
1.4卷积的参数
· Kernel size: 定义卷积核的大小,影响卷积操作的感受野,一般使用3x3,5x5 等
· Stride: 定义遍历图像时卷积核移动的步长
· Channel: 定义卷积运算的输入和输出通道数
· Padding: 定义如何处理样本边界的方式,分为不填充或者对边界填充0,不填充的只对特征图做卷积操作,会使得输出的特征图小于输入的特征图;对边界填充0,可以使得输入和输出的特征图保持一致
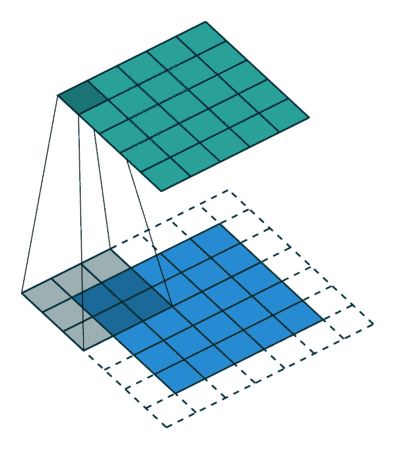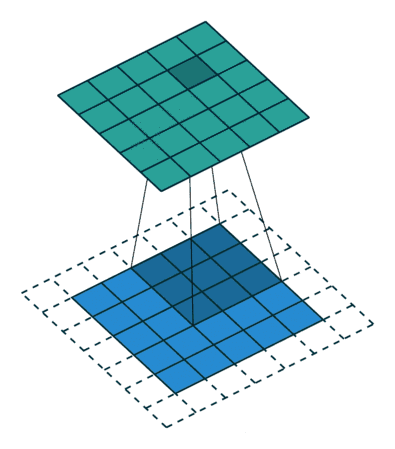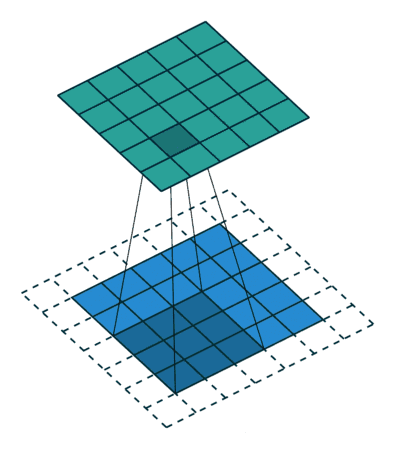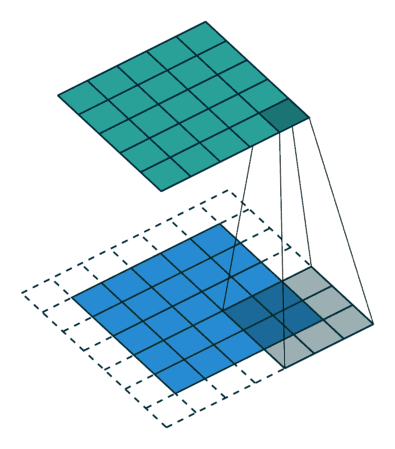
2.千变万化的卷积
常见的卷积类型有很多,根据其操作的区域大致可以分为两类:通道相关性、空间相关性。
· 通道相关性的卷积核改变了卷积在channel维度操作,如:Group Convolution、Depthwise Separable Convolutions;
· 空间相关性的卷积核是改变了卷积在w,h维度的操作。除了这两类近年来也出现了一些新的改进思路:如动态卷积,异构卷积。
2.1通道相关(channel)
Group Convolution
Group Convolution(分组卷积)就是对输入feature map在channel维度进行分组,然后每组分别卷积。
假设输入featuremap的尺寸仍为C∗H∗W,输出feature map的数量为N个,如果设定要分成G个groups,则每组的输入feature map数量为C/G,每组的输出feature map数量为N/G,每个卷积核的尺寸为C/G∗K∗K,卷积核的总数仍为N个,每组的卷积核数量为N/G,卷积核只与其同组的输入feature map进行卷积,卷积核的总参数量为N∗C/G∗K∗K,可见,总参数量减少为原来的1/G。其连接方式如下图右所示,group1输出map数为2,有2个卷积核,每个卷积核的channel数为4,与group1的输入map的channel数相同,卷积核只与同组的输入map卷积,而不与其他组的输入map卷积。
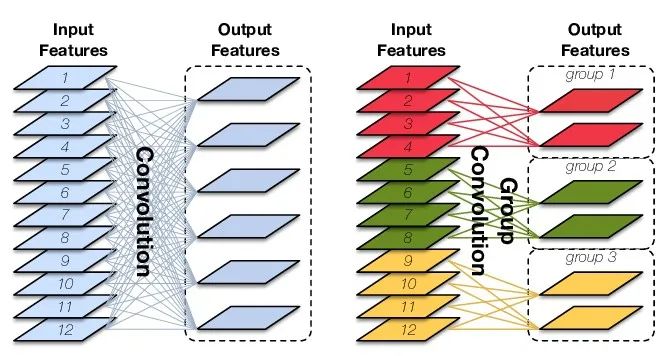
· Depthwise Convolution
当分组数量等于输入map数量,输出map数量也等于输入map数量,即G=C=N、N个卷积核每个尺寸为1∗K∗K时,Group Convolution就成了Depthwise Convolution(深度卷积)。
· Global Depthwise Convolution
更进一步,如果分组数G=N=C,同时卷积核的尺寸与输入map的尺寸相同,即K=H=W,则输出map为 C∗1∗1 即长度为 C 的向量,此时称之为GlobalDepthwise Convolution(GDC),与GlobalAverage Pooling(GAP)的不同之处在于,GDC给每个位置赋予了可学习的权重。
· Shuffled Grouped Convolution
Shuffled GroupedConvolutions 是在 Groupconvolution 计算后对输出的 output feature maps 进行shuffle(打乱)处理,以使得接下来的Group convolutionfilters可在每个group所输出的部分channels构成的集合上进行计算。其操作如下图所示,这么做的原因是为了有效地减小Groups convolution使用导致的Groups间特征互不相通的负面影响。

Depthwise SeparableConvolution
Depthwise SeparableConvolutions(深度可分离卷积) 是由 Depthwise Separable Convolution是将一个完整的卷积运算分解为两步进行,即Depthwise Convolution与Pointwise Convolution。
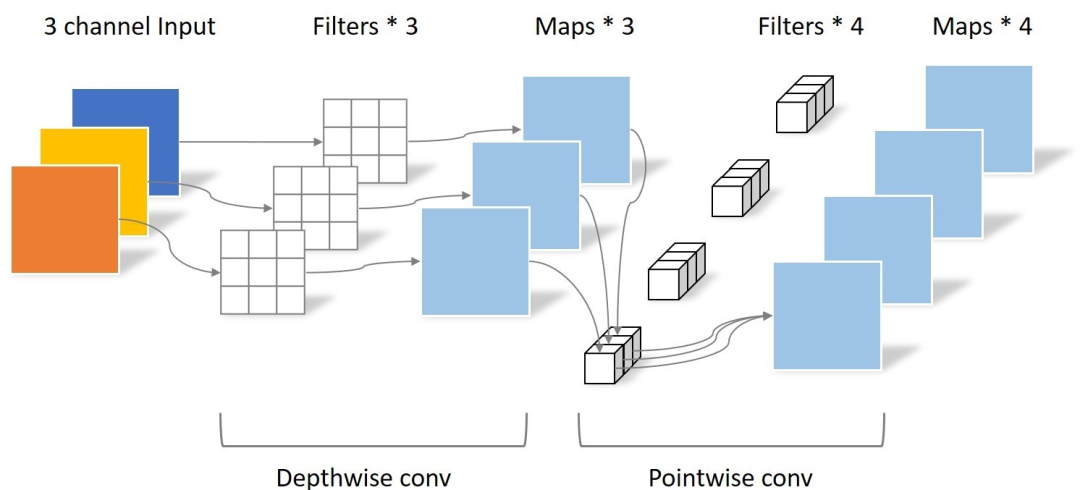
Depthwise Convolution
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。
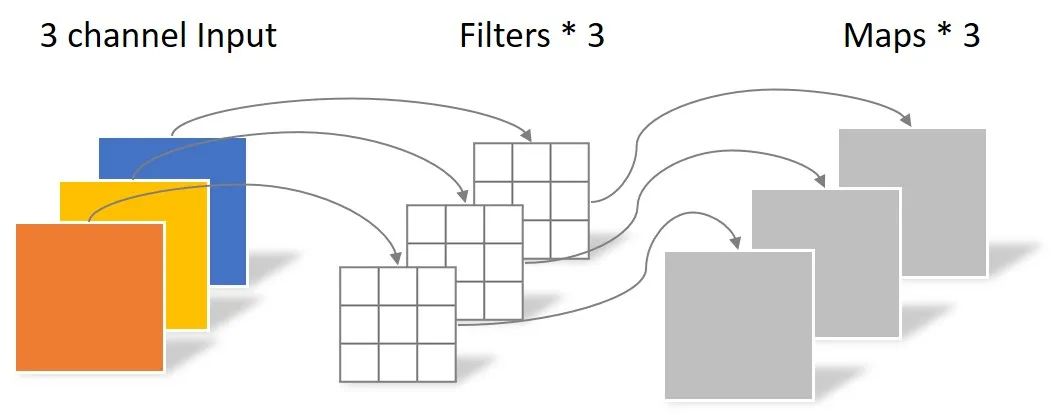
Pointwise Convolution
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。所以这里的卷积运算会将上一步的map在深度方向上进行加权组合,生成新的Feature map。有几个卷积核就有几个输出Feature map。
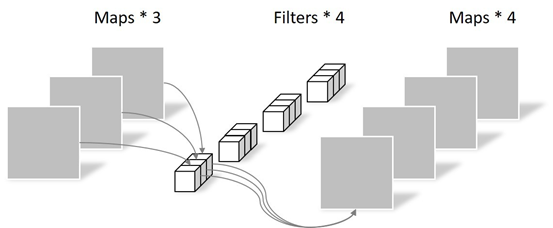
Depthwise SeparableConvolution的参数个数大约是常规卷积的1/3。因此,在参数量相同的前提下,采用Depthwise SeparableConvolution的神经网络层数可以做得更深。
MixConv
MixConv将不同尺度的卷积核融合到一个单独的卷积操作,使其可以易于获取具有多个分辨率的不同模式。如下图是MixConv的结构,将通道分成了多个组,对每个通道组应用不同尺寸的卷积核。作者将其MixConv表示为普通深度卷积的一个简单替换,但可以在ImageNet分类和COCO目标检测上显著地提高MobileNets的准确性和效率。
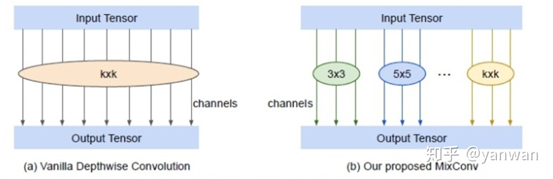
2.2空间相关(Spatial)
Dilated Convolution
Dilated Convolution 就是在常规卷积中引入一个 dilationrate 参数也就是指的是kernel的间隔数量(正常的convolution 是dilatation rate 1)。从下面的动图就可以很好理解了:
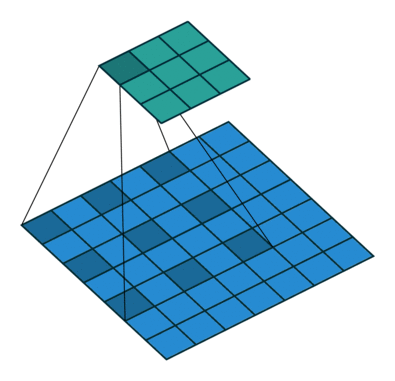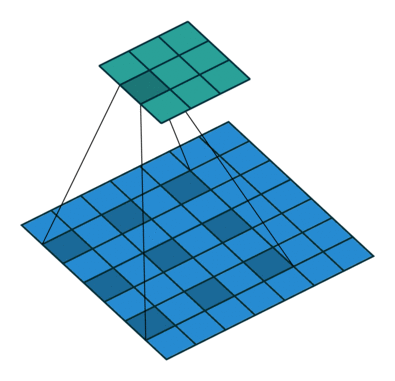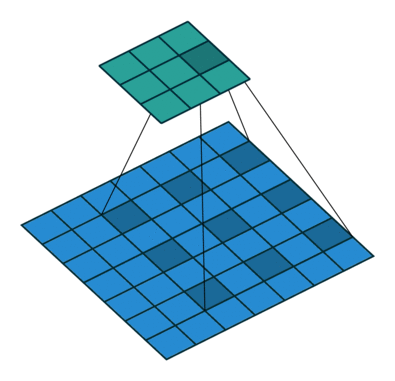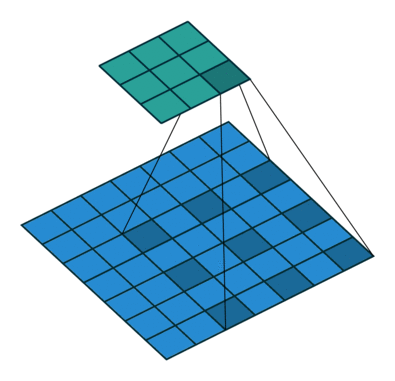
Dilated Convolution
kernel: 3x3, Pading: 0,dilationrate: 2
Dilated Convolutions可以在参数量不变的情况下有效的提高卷积核的感受野。DilatedConvolutions主要应用于图像分割领域,这是由于其可以替代up-sampling和 pooling layer。up-sampling 和 pooling layer会导致内部数据结构丢失;空间层级化信息丢失。
小物体信息无法重建 (假设有四个pooling layer 则 任何小于 2^4 = 16 pixel 的物体信息将理论上无法重建。)在这样问题的存在下,语义分割问题一直处在瓶颈期无法再明显提高精度,而 dilated convolution 的设计就良好地避免了这些问题。
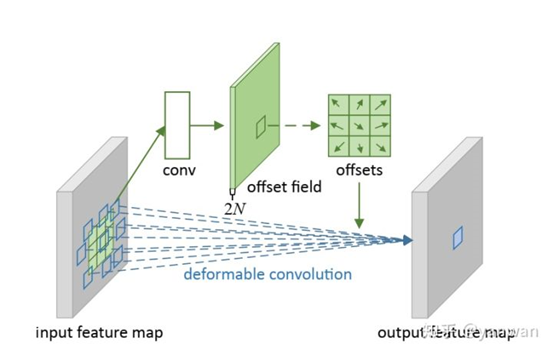
DeformableConvolution
(1) DCN v1
可变形卷积引入了可变形模块的机制,它具有可学习的形状以适应特征的变化。传统上,卷积中由采样矩阵定义的核形状从一开始就是固定的。
可变形卷积使的采样矩阵具有可学习性,允许核的形状适应输入中未知的复杂物体。让我们看看下图来理解这个概念。
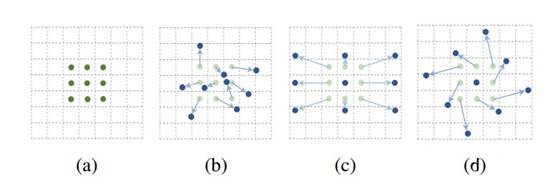
如上图3×3标准卷积和可变形卷积中采样矩阵地图示:
· a 是标准卷积的采样矩阵(绿点);
· b是变形卷积中偏移量增大(浅蓝色箭头)的变形采样位置(深蓝色点);
· c 和 d 是 b 的特例,表明可变形卷积推广了尺度、(各向异性)纵横比和旋转的各种变换;
可变形卷积学习是具有位置偏移的采样矩阵,而不像标准卷积那样使用固定偏移的采样矩阵。偏移量通过附加的卷积层从前面的特征映射中学习。如果将标准卷积表示为:
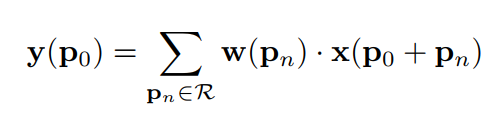
那么可变形卷积可以表示为:
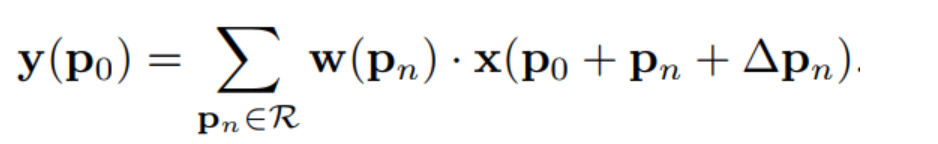
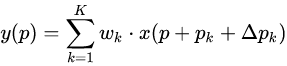
式中,Δpₙ表示加入正常卷积运算的偏移量。pₙ是枚举采样点。现在采样点位于不规则的偏移位置pₙ+∆pₙ,即核的采样位置重新分布,不再是规则矩形,允许采样点扩散成非gird形状。
如下所示,偏移量通过在输入特征映射上应用卷积层来获得。假设原来的卷积操作是3*3的,那么为了学习offsets,需要定义另外一个3*3的卷积层,输出的offset field其实就是原来feature map大小,channel数等于2N(分别表示x,y方向的偏移,这里的N实际上是 kernel 里的 samplinglocation数。如果 3 x 3 的 kernel 的话,N = 9)。这样的话,有了输入的feature map,有了和feature map一样大小的offset field,我们就可以进行deformable卷积运算。所有的参数都可以通过反向传播学习得到。
(2) DCN v2
DCN v1的问题是:可变形卷积有可能引入了无用的区域来干扰我们的特征提取,降低了算法的表现,如下图所示。


因此,在DCNv1的offset基础上,添加每个采样点的权重,如下:
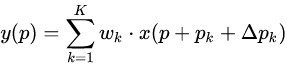
其中,Δpₙ是偏移量,Δm学到的权重。这样的好处是增加了更大的自由度,对于某些不想要的采样点权重可以学成0。
总的来说,DCNv1中引入的偏移量是要寻找有效信息的区域位置,DCN v2中引入权重系数是要给找到的这个位置赋予权重,这两方面保证了有效信息的准确提取。
Spatially SeparableConvolutions
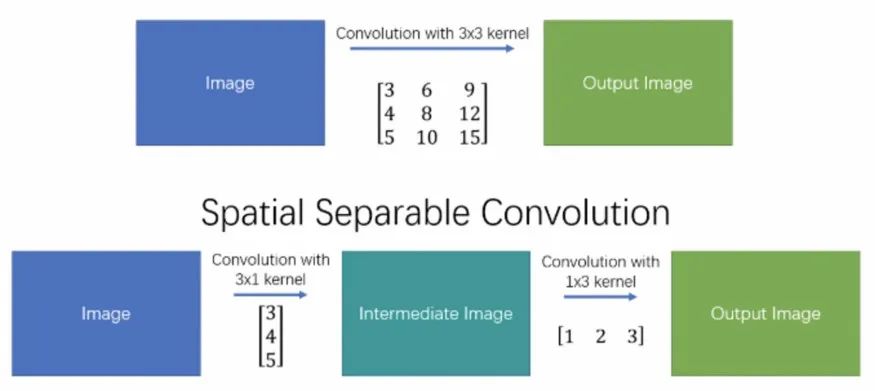
SpatiallySeparableConvolutions将卷积分成两部分,最常见的是把3x3的kernel分解成3x1和1x3的kernel。例如:
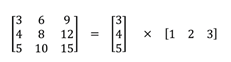
通过这种方式,原本一次卷积要算9次乘法,现在只需要6次。但是SpatiallySeparableConvolutions 有一个缺陷那就是并不是所有卷积核可以分成两个小的卷积核。
FlattenedConvolutions
Flattened Convolutions是将三维卷积核拆分成3个1维卷积核。Flattened Convolutions 计算过程如图(b)。
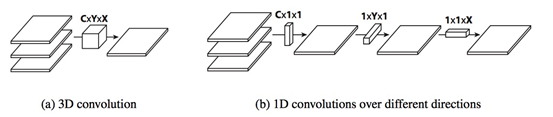
Flattened Convolutions 极大地减少了计算量。FlattenedConvolutions 引入了的不对称卷积,再后来也证实了这种不对称卷积Nx1和1xN,对准确率是有提升的。
2.3新的卷积思路
HetConv 异构卷积
HetConv 是在2019年CVPR提出的一种新的高效卷积方式,它在CIFAR10、ImageNet等数据集超过了标准卷积以及DW+PW的高效卷积组合形式,取得了更高的分类性能。HetConv 主要侧重于设计新的卷积核,传统的卷积和按文中说法称为同构卷积(homogeneousconvolution),即该过滤器包含的所有卷积核都是同样大小(比如在 3 × 3 × 256CONV2D 过滤器中,所有 256 个核都是 3×3 大小),HetConv 是异构卷积(heterogeneous convolution), 即过滤器包含不同大小的卷积核(比如在某个 HetCOnv 过滤器中,256 核有的是 3×3 大小,其余的是 1×1 大小,由参数P控制 1×1 卷积核的数量)。
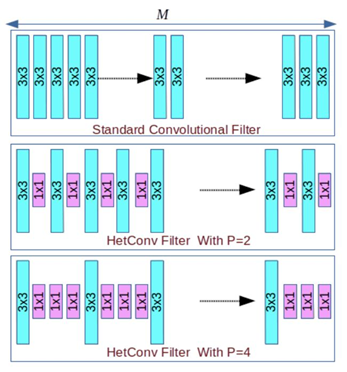
HetConv在ResNet 和 VGG-16 等不同架构上进行了广泛的实验——只是将它们的原始过滤器替换成了HetConv。实验发现,无需牺牲这些模型的准确度就能大幅降低 FLOPs(3 到 8 倍)。
Dynamic Convolution动态卷积
Dynamic Convolution是微软AI在CVPR2020提出的高性能涨点的动态卷积。动态卷积这种新的设计能够在不增加网络深度或宽度的情况下增加模型的表达能力(representation capacity)。动态卷积的基本思路就是根据输入图像,自适应地调整卷积参数。如图1所示,静态卷积用同一个卷积核对所有的输入图像做相同的操作,而动态卷积会对不同的图像(如汽车、马、花)做出调整,用更适合的卷积参数进行处理。简单地来说,卷积核是输入的函数。

动态卷积没有在每层上使用单个卷积核,而是根据注意力动态地聚合多个并行卷积核。注意力会根据输入动态地调整每个卷积核的权重,从而生成自适应的动态卷积。由于注意力是输入的函数,动态卷积不再是一个线性函数。通过注意力以非线性方式叠加卷积核具有更强的表示能力。
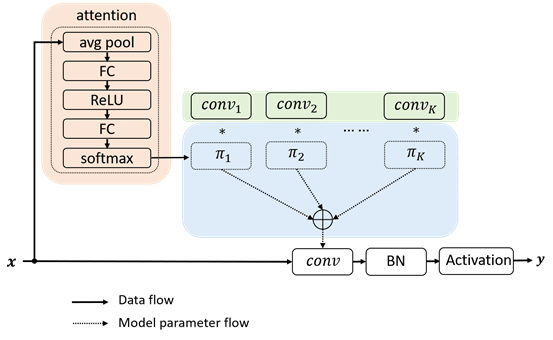
动态卷积可以轻易地嵌入替换现有网络架构的卷积,比如1×1卷积, 3×3卷积,组卷积以及深度卷积。实验表明,动态卷积在 ImageNet 分类和 COCO 关键点检测两个视觉任务上均具有显著的提升。例如,通过在 SOTA 架构 Mobilenet 上简单地使用动态卷积,ImageNet 分类的 top-1 准确度提高了 2.3%,而FLOP 仅增加了 4%,在 COCO 关键点检测上实现了 2.9 的 AP 增益。在关键点检测上,动态卷积在 backbone 和 head 上同样有效。
3.总结
卷积核作为卷积神经网络的基础部分,它的直接影响了神经网络的性能。本文按照卷积核改进思路分为通道相关性和空间相关性,并介绍了近年来主要的卷积方式。新的卷积核提出主要由两种出发点:模型轻量化,在尽量保持模型精度的情况下,减小模型的参数和计算;高精度模型,在尽量不增加模型的计算和参数下,有效的提高模型的精度。简单来说,
· 模型轻量化的有:group/depthwiseconv等,
· 高精度模型的有deformableconv,动态卷积等。
热线电话:0755-23712116
邮箱:contact@shuangyi-tech.com
地址:深圳市宝安区沙井街道后亭茅洲山工业园工业大厦全至科技创新园科创大厦2层2A
