热线电话:0755-23712116
邮箱:contact@shuangyi-tech.com
地址:深圳市宝安区沙井街道后亭茅洲山工业园工业大厦全至科技创新园科创大厦2层2A


归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。


归并排序是一种稳定的排序方法。和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(nlogn)的时间复杂度。代价是需要额外的内存空间。
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:

堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。



计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。 作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
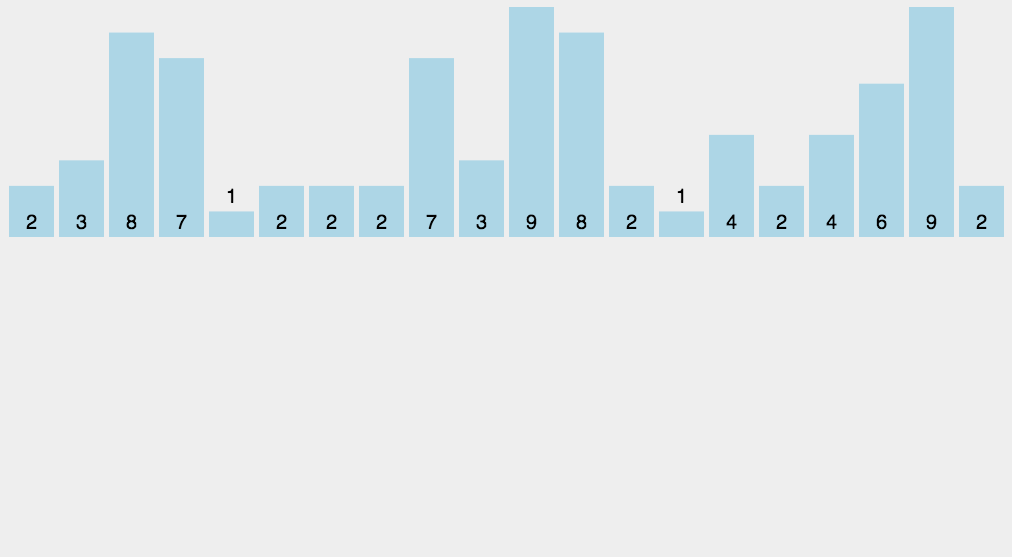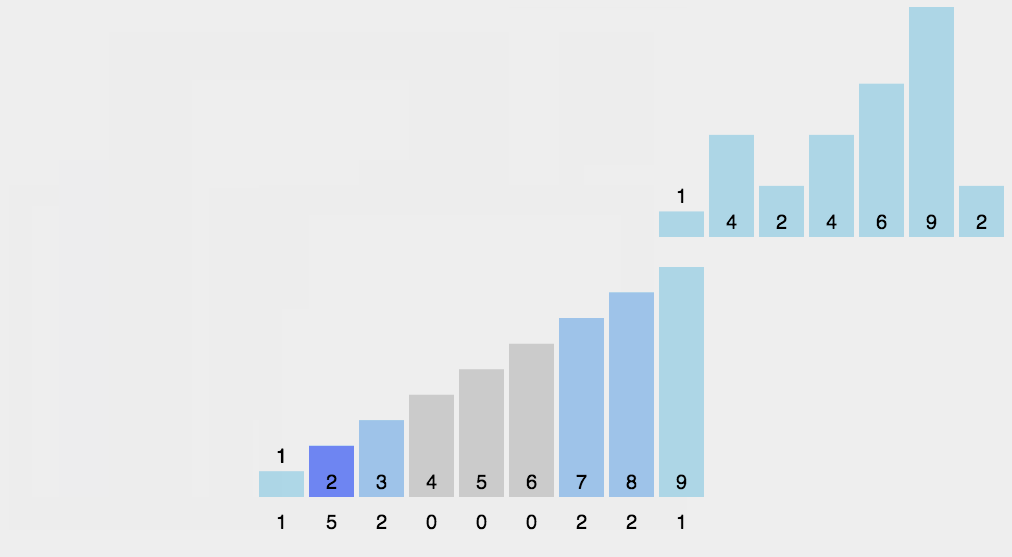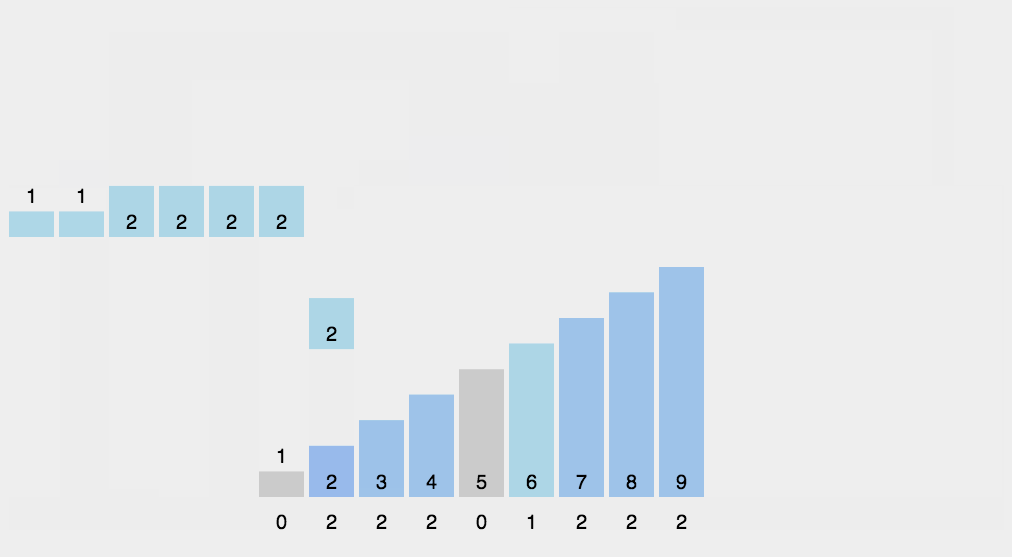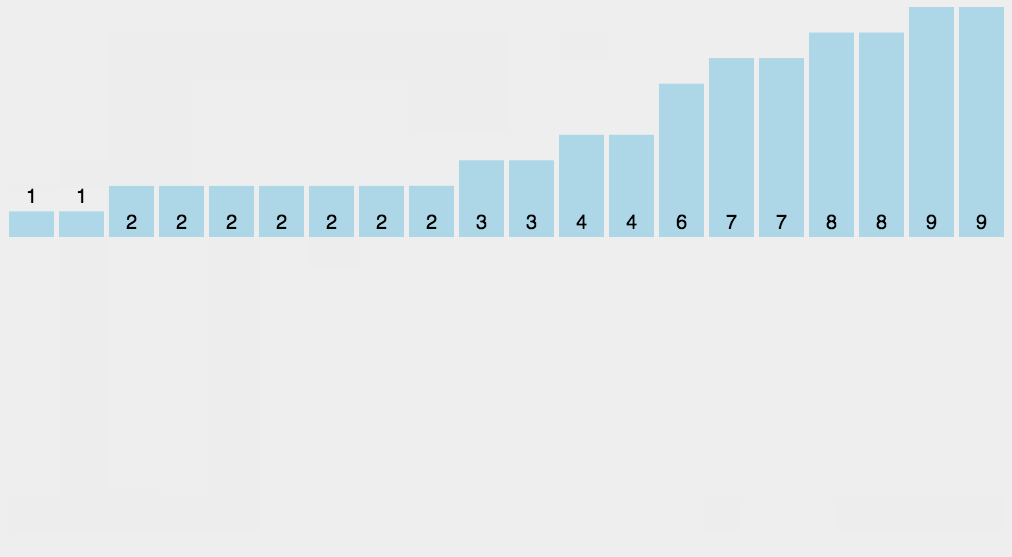

计数排序是一个稳定的排序算法。当输入的元素是 n 个 0到 k 之间的整数时,时间复杂度是O(n+k),空间复杂度也是O(n+k),其排序速度快于任何比较排序算法。当k不是很大并且序列比较集中时,计数排序是一个很有效的排序算法。
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。桶排序 (Bucket sort)的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排)。

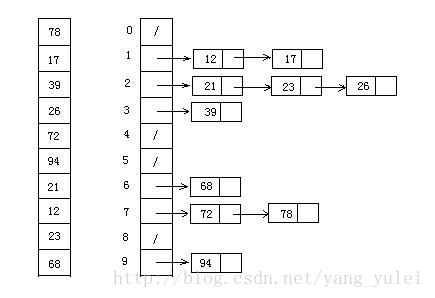

桶排序最好情况下使用线性时间O(n),桶排序的时间复杂度,取决与对各个桶之间数据进行排序的时间复杂度,因为其它部分的时间复杂度都为O(n)。很显然,桶划分的越小,各个桶之间的数据越少,排序所用的时间也会越少。但相应的空间消耗就会增大。
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。

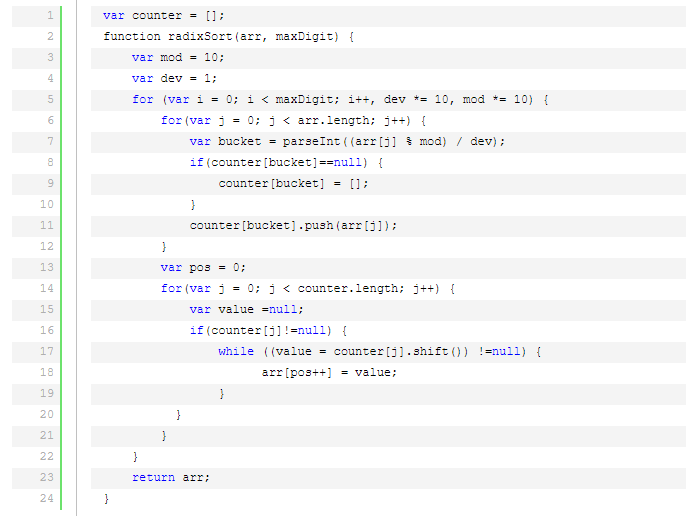
基数排序基于分别排序,分别收集,所以是稳定的。但基数排序的性能比桶排序要略差,每一次关键字的桶分配都需要O(n)的时间复杂度,而且分配之后得到新的关键字序列又需要O(n)的时间复杂度。假如待排数据可以分为d个关键字,则基数排序的时间复杂度将是O(d*2n) ,当然d要远远小于n,因此基本上还是线性级别的。
基数排序的空间复杂度为O(n+k),其中k为桶的数量。一般来说n>>k,因此额外空间需要大概n个左右。
热线电话:0755-23712116
邮箱:contact@shuangyi-tech.com
地址:深圳市宝安区沙井街道后亭茅洲山工业园工业大厦全至科技创新园科创大厦2层2A
